指定したWEBページから画像等のURLを抽出するソフト「Norobusa URL Getter」
投稿日:2017年01月12日
最終更新日:
もくじ
- 「Norobusa URL Getter」の概要
- インストール方法
- 使い方
「Norobusa URL Getter」の概要
「Norobusa URL Getter」は、指定したWEBページから画像等のURLを抽出し、テキストファイルに出力するソフトです。抽出するURLは拡張子やキーワードを用いて絞り込むことが出来るので、画像ファイルのURLだけを取り出すなどの用途にも対応できます。
インストール方法
まずはVectorのダウンロードページからソフトをダウンロードしてきましょう。ダウンロードしたら、ファイルを適当なフォルダに解凍してください。
配置完了後、「Norobusa URL Getter.exe」を実行しましょう。
使い方
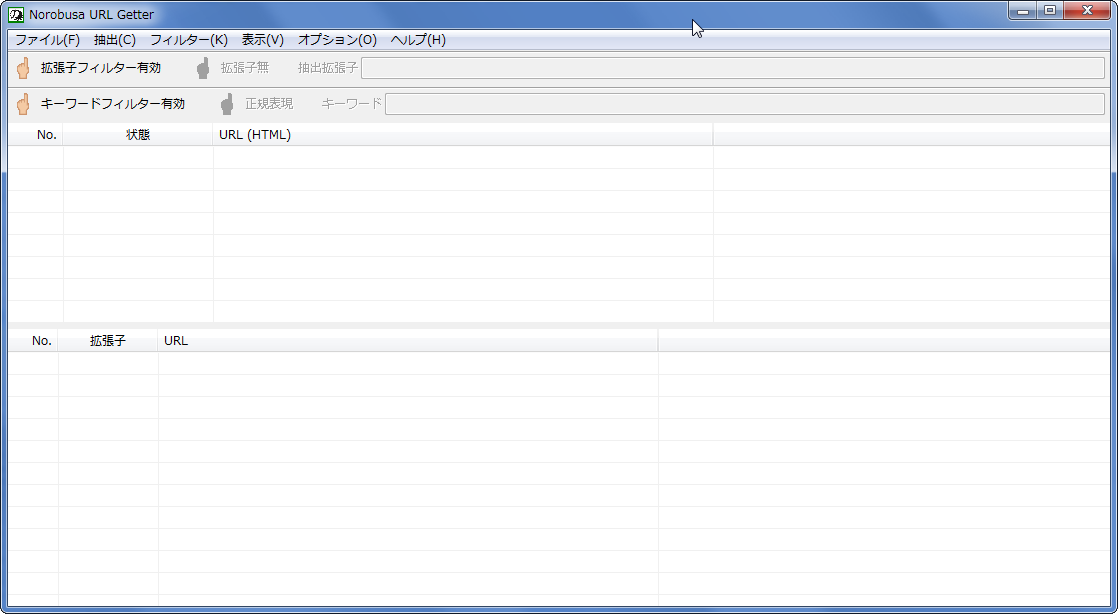
起動したらこんな感じの画面が表示されるはずです。まずはURL抽出を行いたいWEBページのURLを記述したテキストファイルを作成してください。1行につき1URLです。作成完了後、「ファイル」→「ファイルを開く」からURLリストのテキストファイルを読み込みましょう。
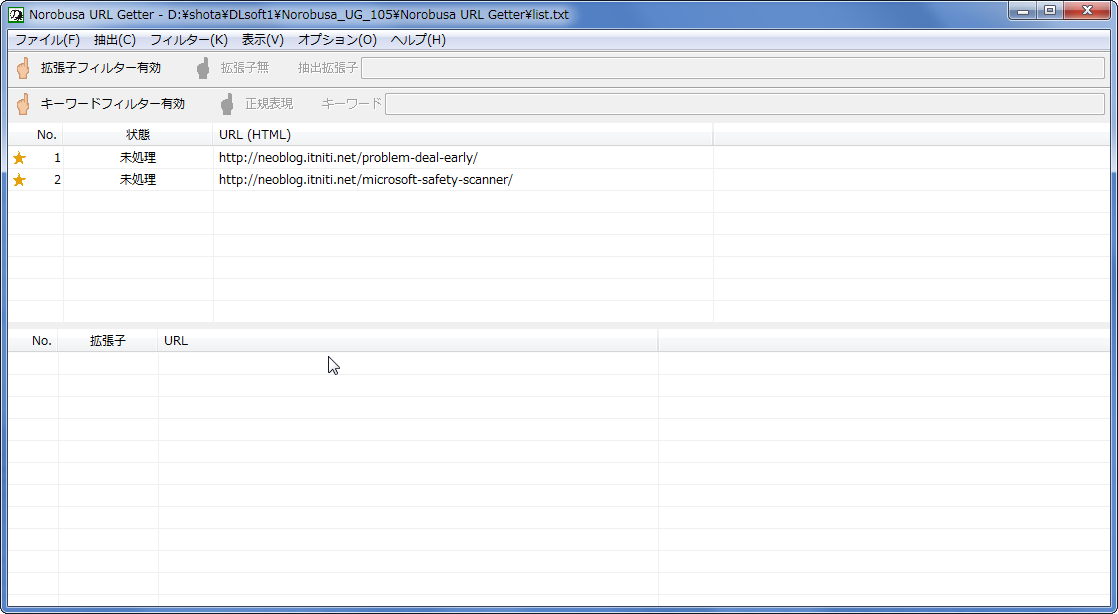
無事にURLが読み込まれました。後はURLを右クリックorメニューバーの「抽出」から「URL抽出実行」を押せば、指定したWEBページからURLが抽出されます。「ファイル」→「抽出したURLをファイルに出力」を押せば、抽出したURLをテキストファイルに出力できます。ただ、何の設定もなしに実行したらURLが無差別に抽出されるので、必要に応じて絞り込むべきです。
URLを絞り込む設定
抽出するURLは、「拡張子」と「キーワード」で絞り込むことが出来ます。拡張子による絞り込みは、画像だけを抽出したい場合などに特に有効と思われます。URLの一部が分かっている場合は、キーワードで絞り込むと良いでしょう。
拡張子フィルター
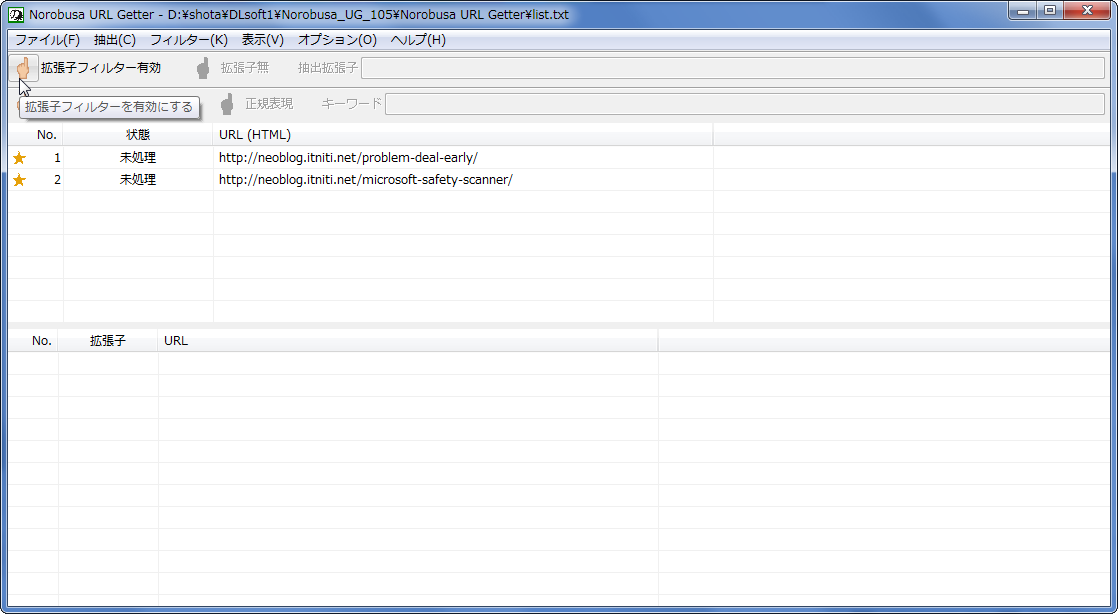
まずは上画像でポイントしているボタンを押すか、「フィルター」→「拡張子フィルター」→「拡張子フィルターを有効にする」をクリックして拡張子フィルターを有効化しましょう。
拡張子がないURLも抽出したい場合は、「拡張子無」の脇にある手のマークをクリックするか、「フィルター」→「拡張子フィルター」→「拡張子の無いURLも抽出」をクリックしてください。拡張子を指定するときは、拡張子をスラッシュで区切って入力しましょう。ドットはあってもなくてもいいです。
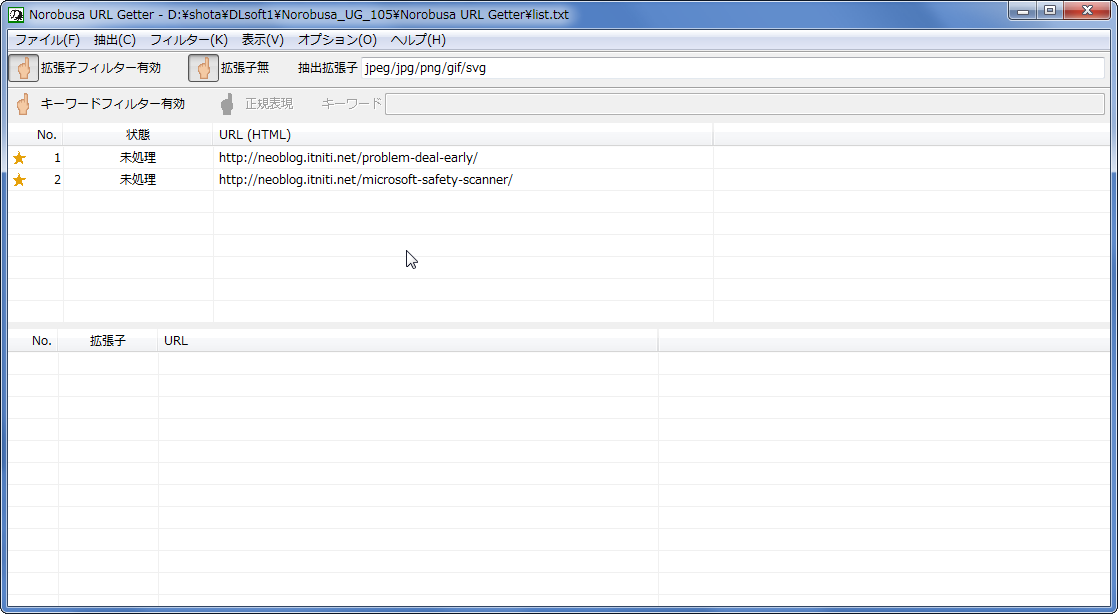
拡張子入力はこんな感じです。なお、「拡張子の無いURLも抽出」を有効化している場合は、拡張子を指定しても拡張子なしのURLが抽出されます。
[VIM]
jpeg/jpg/png/gif/svg
[/VIM]
キーワードフィルター
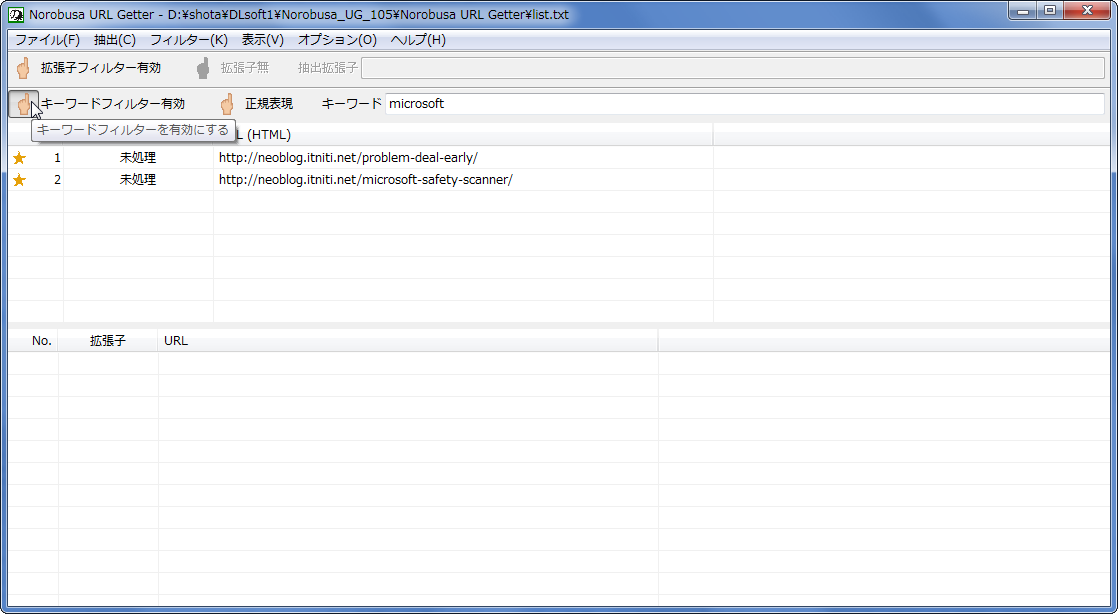
上画像でポイントしているボタンを押すか、「フィルター」→「キーワードフィルター」→「キーワードフィルターを有効にする」をクリックしてキーワードフィルターを有効化しましょう。
キーワード入力欄に、抽出したいURLに含まれている文字列を入力します。正規表現を使いたい場合は、「正規表現」の脇にある手のマークをクリックするか、「フィルター」→「キーワードフィルター」→「キーワードを正規表現にする」をクリックしてください。
いずれにせよ、絞り込みの設定が完了次第、「抽出」→「URL抽出実行」を押せばURL抽出が行われます。「ファイル」→「抽出したURLをファイルに出力」で抽出したURLリストをテキストファイルに出力できるので、そのファイルを本ブログでも使い方を解説しているNorobusa Downloaderに読ませ、ファイルの一括ダウンロードを行うという芸当も出来ます。


